
Completed Projects
NewsReader: “Building structured event indexes of large volumes of financial and economic data for decision making”. EU 7th Framework programme project ICT-2011-8-3164048 (2013-2015)
Project coordinator of NewsReader: a “Recorder of History”, which is a computer program that “reads” daily streams of news and stores exactly what happened, where and when in the world and who has been involved. The program uses the same strategy as humans by building up a story and to merge it with information stored previously. The software does not store separate events but a chain of events according to a story-line. Like humans, the program thus removes duplicate information and complements incomplete information in the news while reading. In the end, it maintains a single story-line for the events. Unlike humans, the recorder will not forget any detail, will be able to recall the complete and true story as it was told, know who told what part of the story and what sources contradicted each other.
NewsReader video January 2015 Hackathon by Marieke van Erp on Vimeo.
The history recorder can be seen as a new way of indexing and retrieving information that helps decision makers to handle billions of news items in archives and millions of incoming news items every day. Current solutions simply result in long lists of potentially relevant items due to the abundance of information. It is up to the user to sift through these results: removing duplication, putting pieces together and separating correct from incorrect information. Likewise, it is often impossible to make truly well-informed decisions. The history recorder is however able to structure these results according to story lines, where it presents the information as a single and complete history.
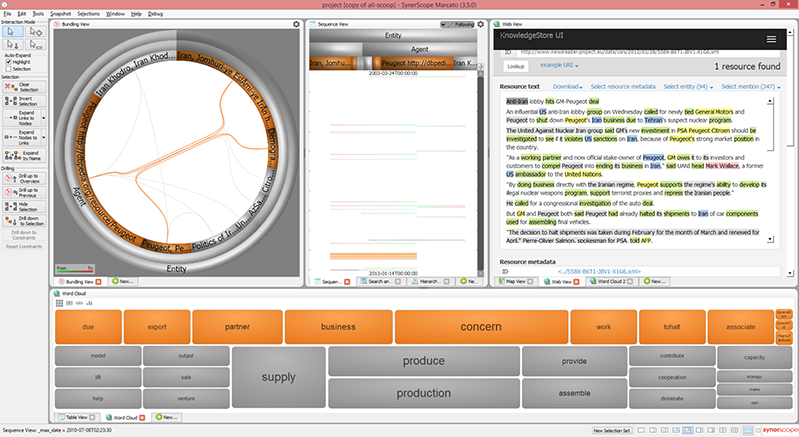 SynerScope‘s visualization: extraction from 1.26M news articles
SynerScope‘s visualization: extraction from 1.26M news articles
In addition to organizing news as stories, the recorder also has the capacity to abstract from individual stories and to find trends and patterns. It can for example provide a quantified overview of types of companies that are involved in take-overs, in specific periods or regions and correlate that with changes in management and profits. Since it keeps track of all the original sources of the information, the recorder can also provide insights in how the story was told. This will tell us about the different perspectives of sources on our news of today and of the past.
- See press release on Newsreader by VU, May 2, 2012
- See radio-interview, FunX Radio, Amsterdam, May 10, 2012
- Vossen invited speaker in Casa Luna, Dutch radio interview on new EU-project NewsReader, Mediapark, Hilversum, October 8, 2012
- announcement video on Youtube by Casa Luna;
- @ Radio 1, NCRV Casa Luna, part 1 (on NewsReader), Hilversum, October 8, 2012;
- @ Radio 1, NCRV Casa Luna, part 2 (live interaction with listeners), Hilversum, October 8, 2012.
- Blog from Marco Leeuwerink on the interview at Casa Luna on Extend Limits.
Reading between the lines: identifying implicit perspectives through linguistic analyses. NWO VENI 2015: Dr. Antske Fokkens (2016-2019)
Summary
Perspectives are conveyed in many ways. Explicit opinions or highly subjective terms are easily identified. However, perspectives are also expressed more subtly. For instance, Nick Wing argues that media describe white suspects (e.g. brilliant, athletic) more positively than black victims (e.g. gang member, drug problems). Ivar Vermeulen (p.c.) observes in a small Dutch corpus that Moroccan perpetrators are easily called thieves (implying generic behavior), where other perpetrators from Dutch only stole something (implying incidental behavior). These observations are anecdotal, but reveal how choices concerning what information to include or how to describe someone’s role may display a specific perspective.
I will investigate how linguistic analyses may be used to identify these more implicit ways of expressing perspectives in text. This research will be carried out in three stages: First, large scale corpus analyses will be applied to identify distributions of semantic roles (what entities do) and other properties assigned to them (their characteristics). In the second stage, generic participants will be linked to the semantic role they imply (e.g. a thief will be linked to the perpetrator of stealing). With these links, we can investigate whether thieves are described differently from people who steal. In the third stage, emotion and sentiment lexica will be used to identify the sentiment associated with descriptions of people enabling research that investigates whether people are depicted positively or negatively.
The research is carried out in the context of digital humanities and social sciences. Evaluation and experimental setup will be guided towards identifying differences in perspective between sources. In addition to correctness of linguistic analyses (intrinsic evaluation), the possibility of using the method for identifying changes in perspective over time (historic research) or differences in perspective between sources (communication science) will be investigated.
BiographyNet: From the Biography Portal of the Netherlands to a Virtual Society of People Past and Present): VU/UvA eScience-project (2012-2016)

Project partner of BiographyNet. The Biography Portal of the Netherlands links a wide variety of Dutch online reference works and data sets, written in different times and from different perspectives, through a limited number of metadata. This project aims to enhance its research potential for historical research on the portalís ‘virtual community’ of the more than 100.000 Dutch people mentioned in the various linked databases. What historical narrative can be generated from digital access to these dictionaries of biography, lexicons and portrait collections? The lead question for the design of a demonstrator is: how can we generate relationships between peoples and events, geographical movements of and networks between people from the Biography Portal and what do they tell historians about the formation of Dutch society and the ‘boundaries of the Netherlands’.
BiographyNet video presentation
The current search engine, although allowing for free full text search, generates only high level search results. As such the portal so far ‘only’ provides a series of linked online resources. It lacks analytic tools to show interconnections, trends, geographical maps and time lines, etc. This research project aims to strengthen the value of this portal and comparable biographical datasets for historical research, by improving the search options and the presentation of its outcomes, starting from the Simple Event Model. This will enable users to trace different perspectives on connections between events, based on (distant or close) connections between persons, places and time. Besides it will create connections between biographical information and museum objects, especially portraits: both in terms of who is being depicted and of who made and/or owned the work. The demonstrator will add a semantic layer on to the current Biography Portal.
The pilot will focus on a qualitative selection of links, relevant to the National Portrait Gallery that is being developed by Rijksmuseum. The series of governors-general portraits at the Rijksmuseum provide a good starting point for this pilot on the networks of these people, their involvement in various events, and their role in the creation of Dutch society. We build on the basis provided by the project Agora, and on the VU-CAMeRA project Semantics of History. From this we derive a clear view on the requirements for representing events on techniques for discovering events and on a shred (computational, historical) frame of reference for interpreting historical events. For text mining, we re-use the framework developed in the Asian-European project.
 The project is a collaboration between the Netherlands eScience Center, Huygens ING and VU University Amsterdam.
The project is a collaboration between the Netherlands eScience Center, Huygens ING and VU University Amsterdam.